发布时间:2024-12-16
“多年以后,面对屏幕,猕猴欧米伽将会回想起,第一次在迷宫中吃下能量豆、追逐幽灵的那个遥远的下午。”
2024年12月3日,《Current Biology》在线发表了题为《人类与猕猴问题解决的语言模型》的研究论文。该研究由中国科学院脑科学与智能技术卓越创新中心(神经科学研究所)杨天明研究组完成。该研究建立了一种新型问题解决层级化决策模型框架——问题解决语言模型(Language of Problem Solving, LoPS),并将其应用于经典街机游戏“吃豆人”的任务范式。通过对人类与猕猴在游戏中的问题解决的定量分析,该研究揭示了两者在问题解决能力上的差异及学习过程中的行为进化模式,为理解大脑实现复杂认知功能的结构化机制提供了重要启示。
在解决问题中形成的思维方式因个体、物种、甚至文化而异。例如同样讲述一个故事,不同的思维会产生截然不同的路径:有人偏爱线性叙事,让故事从山里老和尚的生活缓缓展开;有人选择空间的诗意,将“落霞与孤鹜齐飞,秋水共长天一色”的场景联结,以意象传递深意;还有人像《百年孤独》那样,将时间、地点与人物交织成复杂的网络。而智能的核心特征之一是能够面对复杂的任务规划并执行一系列操作,通过动态调整策略来应对任务中的意外变化。
尽管理解问题解决过程中人类和动物展现的高级认知能力是神经科学与认知科学领域的重要研究方向,但领域常用的相对简单的行为范式往往难以激发足够复杂的行为结构;同时,复杂的行为又没有合适的量化和分析的手段。为了解决这一问题,研究团队改编了经典街机游戏“吃豆人”,设计了一个适用于人类与猕猴的跨物种实验范式(图A)。在实验中,参与者需要控制“吃豆人”在迷宫中收集食物,同时避开敌人(幽灵)的追击,并通过特殊的能量豆改变幽灵的状态以获取更多奖励。猕猴在游戏中可以实时得到果汁奖励。游戏的目标是清除迷宫中的所有食物,但如何规划行动、如何对抗幽灵、何时冒险、何时规避,完全由人类或猕猴自由决定。这一开放的设计,像一面镜子,反映出不同个体在动态复杂环境中的决策模式与策略逻辑。
为了定量分析人类与猕猴在游戏中的问题解决策略,研究团队提出了“问题解决语言模型”(LoPS)。研究者首先发现,人类和猕猴的游戏策略均由一组基础策略(如觅食、躲避、接近能量豆等)组成。参与者的游戏过程可以分解为由不同策略组成的时间序列,这些基础策略通过不同的组合规则构成了更高层次的决策结构。LoPS模型将参与者的策略序列视为一种“语言”,而基础策略则为这一语言中的词单元。模型通过语法归纳算法提取其中的语法——即策略之间的隐藏的依赖关系与层级结构(图A)。LoPS模型揭示,人类参与者表现出比猕猴更复杂的策略语法和更深层次的层级结构,尤其是游戏表现优异的高手玩家。高手玩家通过灵活组合多种策略,不仅能够高效完成游戏中觅食和幽灵捕捉两大核心要素,还能通过“分而治之”的方法,这两个要素串联起来取得更高的得分。相比之下,猕猴的策略语法相对简单,主要集中于觅食任务,且其策略之间的组合层级较浅(图B)。尽管如此,猕猴在长期训练中逐渐进化出更复杂的策略语法,表现出从简单到复杂的学习过程,这说明其问题解决能力是可塑的。
通过LoPS模型,研究者进一步发现在人类参与者中,策略语法的复杂性与游戏表现显著正相关,复杂语法能够帮助玩家更高效地完成任务。此外,人类专家玩家的策略切换反应时间显著低于新手玩家和猕猴,表明复杂语法能够减轻实时决策负担,从而提升行为效率。研究表明,人类和猕猴在问题解决能力上的差异不仅体现在语法复杂性上,还反映在两者的学习机制与表现上。尽管猕猴经过长期训练能够进化出更复杂的策略语法,但其能力仍远不及人类专家玩家。这表明人类在认知进化中发展出了更强的抽象思维与复杂任务规划能力。通过LoPS模型,研究团队提供了量化人类与动物认知能力差异的新方法,并揭示了问题解决能力的结构化特征。
本研究将动物行为研究、认知神经科学与人工智能建模相结合,为理解灵长类动物的高级认知功能提供了新颖实验范式与分析工具。研究团队提出的问题解决语言模型不仅有助于揭示人类智能的独特性,还为未来探索问题解决的神经机制提供了理论框架和实验依据。
本研究由中国科学院脑科学与智能技术卓越创新中心(神经科学研究所)的副研究员杨千里和研究助理竺智华为该研究的共同第一作者,博士后姒若光、博士研究生李昀蔚、英国斯旺西大学的张嘉祥教授在项目的不同阶段给予了支持,杨千里副研究员和杨天明研究员为本论文的通讯作者。本研究是杨天明研究组在灵长类抉择相关的高级认知功能方向系列研究的延续(eLife 2022)。该工作获得了中国科学院战略性先导科技专项、国家科技创新2030重大计划、国家自然科学基金、江苏省自然科学基金前沿引领技术专项、中国科学院青年创新促进会、欧盟“地平线2020”研究与创新计划、中国国家留学基金委的资助。
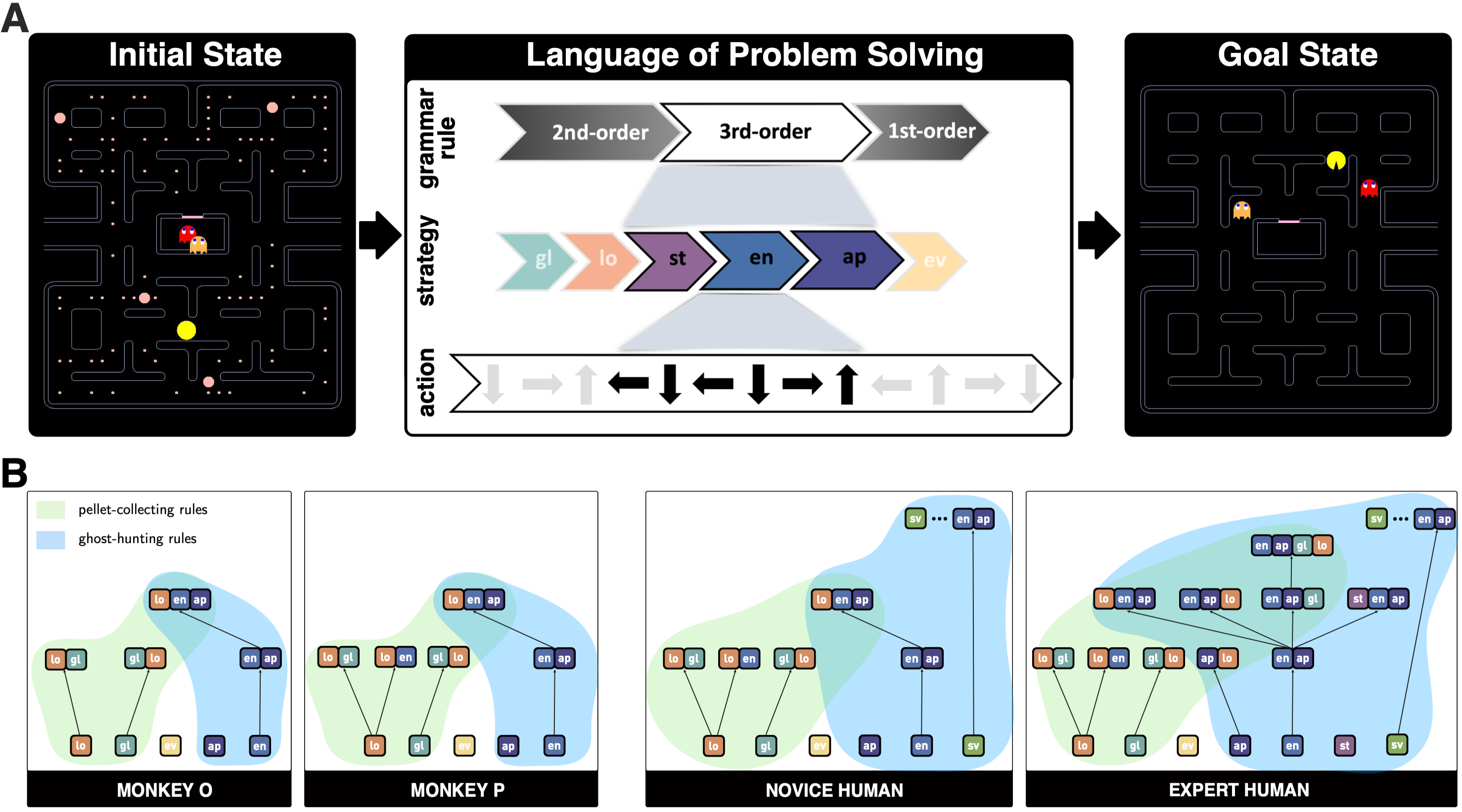
图注(A)LoPS 模型将问题解决概念化为一个将初始状态转化为目标状态的分层结构序列。在这个层次结构的顶端是语法规则的序列,它描述了游戏计划并规定了策略如何连接。在底层,这些策略通过实际的操纵杆动作来实现。策略的缩写如下:lo 表示局部觅食(local);gl 表示全局觅食(global);ev 表示躲避敌人(evade);st 表示停留(stay);ap 表示接近对手(approach);en 表示获取能量豆(energizer)。
(B) LoPS 语法用于描述各两个猕猴和人类被试的策略组合。每个方块代表一个基础策略。高阶依赖规则通过连接两个子单元构建而成。绿色和蓝色阴影分别表示觅食和追捕的策略语法。
 附件下载:
附件下载: 